Abstract
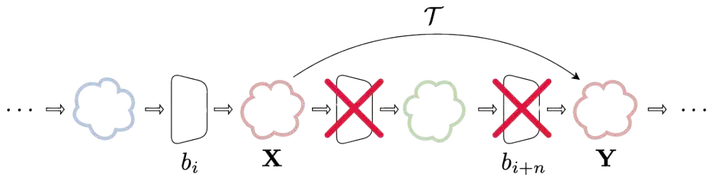
Foundation Models have shown impressive performance in various tasks and domains, yet they require massive computational resources, raising concerns about accessibility and sustainability. Previous attempts to reduce foundation model size fall short of fully addressing the problem, as they end up increasing computational load through additional training steps. Recent works reveal that deep neural networks exhibit internal representation similarities. While inter-network similarities have enabled techniques such as model stitching and merging, intra-network similarities remain underexplored for improving efficiency. In this paper, we propose Transformer Blocks Approximation (TBA), a novel method that leverages intra-network similarities to identify and approximate transformer blocks in large vision models. TBA replaces these blocks using lightweight, closed-form transformations, without retraining or fine-tuning the rest of the model. The proposed method reduces the number of parameters while having minimal impact on the downstream task. We validate the effectiveness and generalizability of TBA through extensive experiments across multiple datasets (e.g., Imagenet-1k and CIFAR100) and state-of-the-art pretrained vision models (e.g, ViT, DiNO-v2, and DEiT).
Irene Cannistraci
Postdoctoral researcher, ETH Zürich
I am a Postdoctoral researcher passionate about Deep Learning.